Logstash Multiline Tomcat and Apache Log Parsing
12 Jan 2014
Update: The version of Logstash used in the example is out of date, but the mechanics of the multiline plugin and grok parsing for multiple timestamps from Tomcat logs is still applicable. I have published a new post about other methods for getting logs into the ELK stack.
Additionally, the multiline filter used in these examples is not threadsafe. I have an updated example using the multiline codec with the same parsers in the new post.
Once you’ve gotten a taste for the power of shipping logs with Logstash and analyzing them with Kibana, you’ve got to keep going. My second goal with Logstash was to ship both Apache and Tomcat logs to Elasticsearch and inspect what’s happening across the entire system at a given point in time using Kibana. Most of the apps I write compile to Java bytecode and use something like log4j for logging. The logging isn’t always the cleanest and there can be several conversion patterns in one log.
Log Format
Parsing your particular log’s format is going to be the crux of the challenge, but hopefully I’ll cover the thought process in enough detail that parsing your logs will be easy.
Apache Logs
The Apache log format is the default Apache combined pattern ("%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\""):
12.34.56.78 - - [09/Jan/2014:04:02:26 -0800] "GET / HTTP/1.1" 200 43977 "-" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)"
123.4.56.7 - - [09/Jan/2014:04:02:26 -0800] "GET /financing/incentives HTTP/1.1" 200 20540 "https://www.google.com/" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.41 Safari/537.36"
123.45.67.89 - - [09/Jan/2014:04:02:28 -0800] "GET /static/VEAMUNaPbswx4l9JeZqItoN6YKiVmYY84EJKnPKSPPM.css HTTP/1.1" 200 6497 "http://www.example.com/financing/incentives" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.41 Safari/537.36"
123.45.67.89 - - [09/Jan/2014:04:02:28 -0800] "GET /static/u5Uj9e2Cc98JPkk2CIHl4SGWcqeQ0YU9O7Ua61z9Qdi.js HTTP/1.1" 200 6192 "http://www.example.com/financing/incentives" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.41 Safari/537.36"
123.45.67.89 - - [09/Jan/2014:04:02:28 -0800] "GET /static/ZiQCg9sERShna8pay7mOZZdbUwqH6n6s9bbmpJhOzpo.css HTTP/1.1" 200 626 "http://www.example.com/financing/incentives" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.41 Safari/537.36"Tomcat Logs
The Tomcat log format in this example is a bit more mixed, with a combination of Tomcat’s SimpleFormatter and a customized Log4j conversion pattern ("%d{yyyy-MM-dd HH:mm:ss,SSS ZZZ} | %p | %c - %m%n"). Here’s an example of the combined log:
Jan 9, 2014 7:13:13 AM org.apache.tomcat.util.http.Parameters processParameters
INFO: Character decoding failed. Parameter [dcp] with value [ppn.%epid!.] has been ignored. Note that the name and value quoted here may be corrupted due to the failed decoding. Use debug level logging to see the original, non-corrupted values.
Note: further occurrences of Parameter errors will be logged at DEBUG level.
2014-01-09 17:32:25,527 -0800 | ERROR | com.example.controller.ApiController - Request exception
javax.xml.ws.WebServiceException: Failed to access the WSDL at: https://api.example.com/DataServices/Data?WSDL. It failed with:
Connection reset.
at com.example.webservices.Data.<init>(Data.java:50)
at com.example.service.soap.DataService.submitRequest(DataService.groovy:28)
at com.example.service.request.RequestService.addRequest(RequestService.groovy:26)
at com.example.controller.ApiController.request(ApiController.groovy:692)
at grails.plugin.cache.web.filter.PageFragmentCachingFilter.doFilter(PageFragmentCachingFilter.java:200)
at grails.plugin.cache.web.filter.AbstractFilter.doFilter(AbstractFilter.java:63)
at org.apache.jk.server.JkCoyoteHandler.invoke(JkCoyoteHandler.java:190)
at org.apache.jk.common.HandlerRequest.invoke(HandlerRequest.java:311)
at org.apache.jk.common.ChannelSocket.invoke(ChannelSocket.java:776)
at org.apache.jk.common.ChannelSocket.processConnection(ChannelSocket.java:705)
at org.apache.jk.common.ChannelSocket$SocketConnection.runIt(ChannelSocket.java:898)
Caused by: java.net.SocketException: Connection reset
... 17 moreThis is a somewhat arbitrary non-default conversion pattern, but I’ll go into greater detail below on the parsing details as well as providing some handy resources on building pattern matchers.
The Logstash Config
To understand the filter section, we must first have a look at the input. I defined four tcp inputs because I piped logs from four different servers into Logstash and wanted to be able to label them as such. As you can see below, each input adds a "server" field that identifies which server the log came from (given other circumstances, this may not be necessary):
input {
tcp {
type => "apache"
port => 3333
add_field => { "server" => "prod1" }
}
tcp {
type => "apache"
port => 3334
add_field => { "server" => "prod2" }
}
tcp {
type => "tomcat"
port => 3335
add_field => { "server" => "prod1" }
}
tcp {
type => "tomcat"
port => 3336
add_field => { "server" => "prod2" }
}
}Use the following Netcat command with TCP inputs and local log files: nc localhost 3333 < prod1/access.log. I realize that the pipe input would have worked as well, and if we were running this on a production system the configuration would be different, but I’ll address that later.
Filter Config
There’s quite a bit of nuance in the filter config that was not immediately apparent to me. First off, in the most recent versions of Logstash, the if/elseif/else logic is preferred to the grep filter. There are a lot of great examples on the web that haven’t been updated to use the new convention.
The Apache processing is something I’ve detailed in a previous post, but it is important to note the added date filter. This filter helps Logstash understand the exact time the event occurred. You’ll notice that the time format matches the timestamp in the Apache logs.
filter {
if [type] == "apache" {
grok {
patterns_dir => "/Users/lanyonm/logstash/patterns"
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
...The multiline filter is the key for Logstash to understand log events that span multiple lines. In my case, each Tomcat log entry began with a timestamp, making the timestamp the best way to detect the beginning of an event. The challenge was that there were multiple timestamp formats. Here are two examples:
Jan 9, 2014 7:13:13 AM2014-01-09 17:32:25,527 -0800
These weren’t entirely standard patterns, so I had to customize grok patterns to match. The following patterns can be found in my grok-patterns gist:
CATALINA_DATESTAMP %{MONTH} %{MONTHDAY}, 20%{YEAR} %{HOUR}:?%{MINUTE}(?::?%{SECOND}) (?:AM|PM)
TOMCAT_DATESTAMP 20%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{HOUR}:?%{MINUTE}(?::?%{SECOND}) %{ISO8601_TIMEZONE}Using these two patterns, we are able to construct the multiline pattern to match both conversion patterns. The negate and previous mean that each line will log-line rolls into the previous lines unless the pattern is matched.
if [type] == "tomcat" {
multiline {
patterns_dir => "/Users/lanyonm/logstash/patterns"
pattern => "(^%{TOMCAT_DATESTAMP})|(^%{CATALINA_DATESTAMP})"
negate => true
what => "previous"
}
}The next thing to do is parse each event into its constituent parts. In the Tomcat log example above, the timestamp is followed by a logging level, classname and log message. Grok already provides some of of these patterns, so we just had to glue them together. Again, because there are two different syntaxes for a log statement, we have two patterns:
CATALINALOG %{CATALINA_DATESTAMP:timestamp} %{JAVACLASS:class} %{JAVALOGMESSAGE:logmessage}
TOMCATLOG %{TOMCAT_DATESTAMP:timestamp} \| %{LOGLEVEL:level} \| %{JAVACLASS:class} - %{JAVALOGMESSAGE:logmessage}We see some of the filter nuance below. These two patterns can be checked against an event by specifying the match with a hash of comma-separated keys and values. The grok filter will attempt to match each pattern before failing to parse. The filter’s match documentation isn’t quite perfected on this point yet. Have a look at the grok filter below:
if "_grokparsefailure" in [tags] {
drop { }
}
grok {
patterns_dir => "/Users/lanyonm/logstash/patterns"
match => [ "message", "%{TOMCATLOG}", "message", "%{CATALINALOG}" ]
}
date {
match => [ "timestamp", "yyyy-MM-dd HH:mm:ss,SSS Z", "MMM dd, yyyy HH:mm:ss a" ]
}Inevitably, there will be mess in your logs that doesn’t conform to your grok parser. You can choose to drop events that fail to parse by using the drop filter inside a conditional as shown on the second line above. Where do [tags] come from you might ask? Tags can be applied to events at several points in the processing pipeline. For example, when the multiline filter successfully parses an event, it tags the event with "multiline".
You can also see that the date filter can accept a comma separated list of timestamp patterns to match. This allows either the CATALINA_DATESTAMP pattern or the TOMCAT_DATESTAMP pattern to match the date filter and be ingested by Logstash correctly.
Output
The output is simply an embedded Elasticsearch config as well as debugging to stdout. If you’d like to see the full config, have a look at the gist.
Grok Patterns
There’s no magic to grok patterns (unless the built-ins work for you). There are however a couple resources that can make your parsing go faster. First is the Grok Debugger. You can paste messages into the Discover tab and the Debugger will find the best matches against the built in patterns. Another regex assistant I use is RegExr. I have the native app, but the web page is nice too.
The full list of patterns shipped with Logstash can be found on GitHub, and the ones I used can be found in this Gist. If you’re not into clicking links, here are the important ones:
JAVACLASS (?:[a-zA-Z0-9-]+\.)+[A-Za-z0-9$]+
JAVALOGMESSAGE (.*)
# MMM dd, yyyy HH:mm:ss eg: Jan 9, 2014 7:13:13 AM
CATALINA_DATESTAMP %{MONTH} %{MONTHDAY}, 20%{YEAR} %{HOUR}:?%{MINUTE}(?::?%{SECOND}) (?:AM|PM)
# yyyy-MM-dd HH:mm:ss,SSS ZZZ eg: 2014-01-09 17:32:25,527 -0800
TOMCAT_DATESTAMP 20%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{HOUR}:?%{MINUTE}(?::?%{SECOND}) %{ISO8601_TIMEZONE}
CATALINALOG %{CATALINA_DATESTAMP:timestamp} %{JAVACLASS:class} %{JAVALOGMESSAGE:logmessage}
# 2014-01-09 20:03:28,269 -0800 | ERROR | com.example.service.ExampleService - something compeletely unexpected happened...
TOMCATLOG %{TOMCAT_DATESTAMP:timestamp} \| %{LOGLEVEL:level} \| %{JAVACLASS:class} - %{JAVALOGMESSAGE:logmessage}The Kibana Dashboard
As I mentioned at the top, the goal of this endeavor was to be able to correlate Apache and Tomcat logs. We often find ourselves asking what a user had been doing on the website when he or she encountered a server error. Elasticsearch and Kibana can put all logs on the same timeline. The production system whose logs I used for experimentation has a pair of servers, each hosting a Tomcat instance and an Apache instance whose logs are divided between static (CDN cached) and non-static requests. I configured a Kibana dashboard so it would display the static and non-static web requests separately as well as separate the application logs per server.
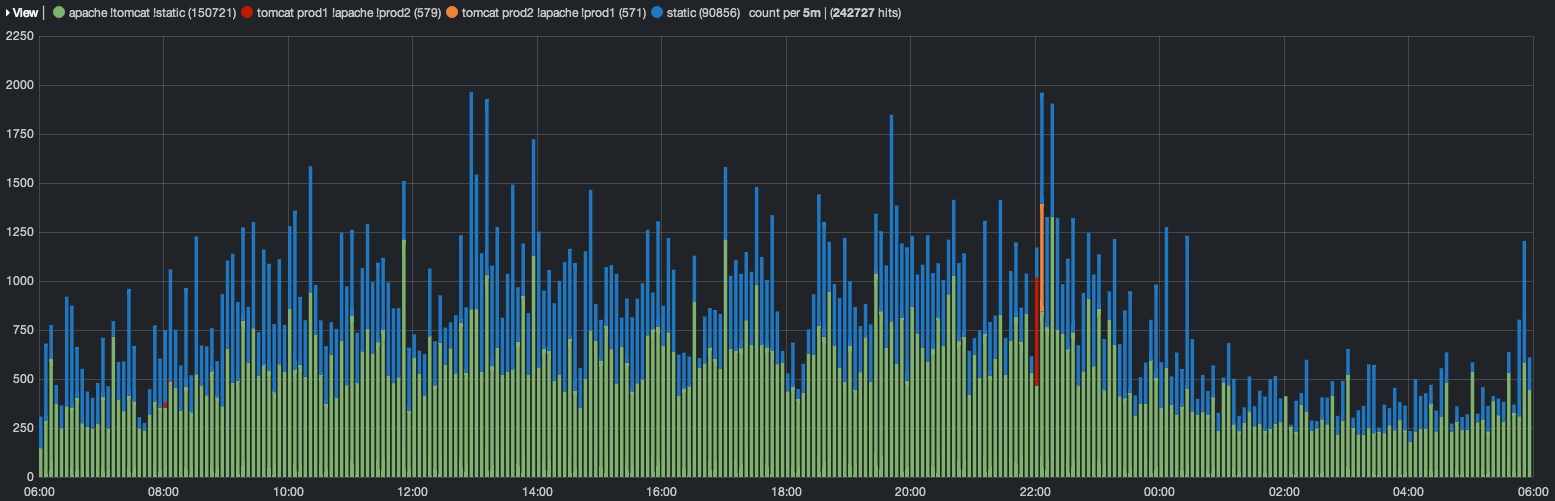
You can see the obvious red and orange areas where a deploy rolled through the system. The colors could be further tweaked to show API calls vs. html pages or to further break down the static content into its constituent mime types. The json representation of the dashboard is here.
If you’re new to Kibana and you’d like to use this dashboard, you can download the json and from the Kibana UI and load the dashboard from disk using the json.
Try It Yourself
I wrote a handy script that can be used in conjunction with other files in the gist:
It should be as easy as ./logstash.sh. If you’re testing out new patterns for your particular log format I would suggest commenting out the embedded Elasticsearch output and the -- web (which runs Kibana) from the shell script.
In Production
One caveat I’d like to make is that the configurations I’ve presented here would not be suitable in production. For example, you would want to use a standalone Elasticsearch instance. The config would also be simpler because each log shipper would be on its respective server and the input would likely be a file. You could easily make an argument for a Logstash process per server that information if being collected from as well.